在当今数据驱动的时代,数据已不再是简单的记录,而是洞察未来的水晶球。作为一名现代“数据工匠”,欲从海量信息中雕琢出价值的瑰宝,不仅需要敏锐的洞察力与严谨的分析思维,更离不开一套强大、高效且适配的“利器”——大数据分析工具与服务。这正是“工欲善其事,必先利其器”在数据科学领域的核心体现。
一、 基石与框架:大数据处理的底层利器
大数据分析的第一步,是处理规模庞大、类型多样、产生迅速的数据集。为此,一系列分布式计算框架应运而生,成为数据工匠工作台的基石。
- Hadoop生态系统:作为开源分布式处理的先驱,以其HDFS(分布式文件系统)和MapReduce(计算模型)为核心,构建了存储与批处理的基础。其上的Hive(数据仓库工具)、HBase(列式数据库)等,为结构化与非结构化数据的处理提供了经典范式。
- Spark:以其内存计算和卓越的速度,在批处理、流处理、机器学习和图计算等领域后来居上。Spark SQL、Spark Streaming等组件,让复杂的数据处理任务变得更为高效和统一。
- Flink:作为真正的流处理优先框架,以其低延迟、高吞吐和精确的状态一致性,在实时分析领域占据了重要地位。
这些框架如同工匠的车间与重型机床,负责将原始、粗糙的“数据原料”进行初步的切割、打磨与成型。
二、 分析与挖掘:从数据到洞察的核心工具集
当数据被有效处理后,便进入了分析与价值挖掘阶段。此阶段的工具更贴近分析师的直接操作。
- 编程语言与库:
- Python:凭借其简洁语法和强大的生态(如Pandas用于数据处理,NumPy用于科学计算,Scikit-learn、TensorFlow、PyTorch用于机器学习与深度学习),已成为数据科学家的首选“瑞士军刀”。
- R语言:在统计分析与可视化方面具有深厚传统,拥有大量专业的统计包(如ggplot2, dplyr),是学术研究和统计建模的利器。
- 交互式分析与可视化平台:
- Jupyter Notebook / Lab:提供了交互式编程和数据探索的绝佳环境,支持代码、文本、公式和可视化结果融为一体,是沟通想法、进行探索性分析的理想工具。
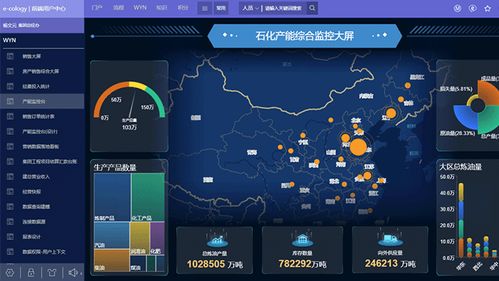
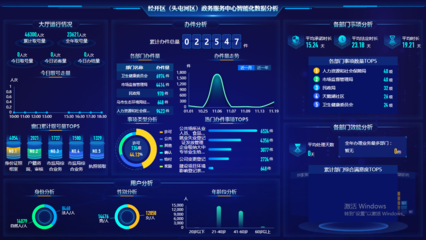
- 商业智能(BI)工具:如Tableau、Power BI、FineBI等。它们通过直观的拖拽界面,将复杂的数据转化为交互式仪表板和易于理解的图表,极大地降低了数据可视化和报告制作的门槛,是向业务部门传递洞察的“桥梁”。
- 机器学习与AI平台:
- AutoML工具(如H2O.ai, Google AutoML):自动化了模型选择、特征工程和超参数调优等复杂步骤,让数据分析师能更专注于业务问题本身。
- 云端AI服务:各大云平台提供的预训练模型和API(如计算机视觉、自然语言处理),让高级分析能力变得触手可及。
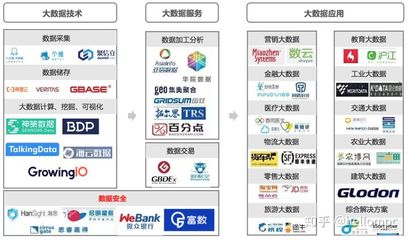
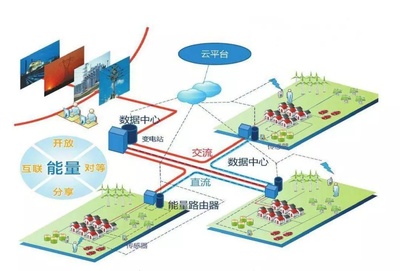
三、 云端赋能:大数据即服务的未来范式
随着云计算的发展,“大数据服务”已从自建工具集的模式,演变为灵活、可扩展的“即服务”(X as a Service)模式。这为数据工匠提供了更强大的外脑和更高效的基础设施。
- 数据存储与计算服务:AWS的S3、Redshift;Azure的Blob Storage、Synapse Analytics;阿里云的OSS、MaxCompute等。它们提供了弹性的存储空间和近乎无限的计算资源,省去了维护硬件集群的繁重负担。
- 数据分析平台即服务(PaaS):如Google BigQuery、Snowflake等云原生数据仓库,以及Databricks(基于Spark的云平台)。它们将计算与存储分离,实现了秒级的弹性伸缩和按需付费,让分析师能直接专注于SQL查询和数据分析。
- 端到端的数据管道与治理服务:云厂商提供的全托管数据集成服务(如AWS Glue、Azure Data Factory)、数据目录和数据治理工具,帮助组织自动化数据流水线,并确保数据的质量、安全与合规。
匠心与利器的融合
“工欲善其事,必先利其器”对于数据工匠而言,意味着两层含义:一是要深刻理解业务之“事”,明确分析目标;二是要精通并善用工具之“器”,提升从数据到价值的转化效率。
优秀的数据工匠,不会局限于单一工具,而是根据任务场景,灵活搭配从开源框架到商业软件,从本地部署到云端服务的最佳组合。他们明白,工具是思维的延伸,服务是能力的拓展。在快速演进的大数据生态中,保持对新兴工具与服务的好奇心与学习能力,本身就是在打磨最重要的“器”——自身与时俱进的技艺与认知。唯有如此,才能在数据的矿山中,持续开采出驱动决策、创造价值的真金。